Industry Insights
How Unsupervised Machine Learning Benefits Industrial Automation
Introduction
The industrial Internet of Things (IIoT), Industry 4.0, cyber-physical systems. The modern industrial environment is filled with sensors and smart components. And, together, all those devices produce a rich trove of data.
That data, untapped in most factories today, is fuel for a wide range of new and exciting applications. In fact, according to IBM, the average factory generates a terabyte of production data daily. Only about 1% of that data is converted into actionable insights, however.1
The A3 whitepaper titled “Intelligent Automation: 6 AI Applications that are Changing Industry”, highlights six application categories that are thirsting for such data. Machine learning (ML) is one foundational technology that is primed to leverage that data and unlock a tremendous amount of value. Using training data, ML systems can build mathematical models to teach a system to perform a specific task without explicit instruction.
Machine learning uses algorithms acting on data to make decisions largely without human intervention. The most common form of ML used in the industrial automation space is supervised ML, which trains the model using large sets of historical data labeled by humans (i.e., humans supervise the training of the algorithm). That’s very useful for well-understood issues like bearing defects, lubrication breakdown, or product flaws. Where supervised ML fall short is in cases for which sufficient historical data is unavailable, when labeling is too time-consuming or expensive, or when users aren’t sure exactly what they’re looking for in the data. This is when unsupervised ML comes into play.
Unsupervised ML is designed to act on unlabeled data using algorithms that excel at identifying patterns and pinpointing anomalies in data. Properly applied, unsupervised ML serves a variety of industrial automation use cases ranging from condition monitoring and performance testing to cyber security and asset management.
Setting the Context
Before we can discuss unsupervised ML, we need to do a quick review of supervised ML (for a more detailed discussion of supervised ML and its application to predictive maintenance, click here). Supervised ML is simpler to execute than unsupervised ML. With a properly trained model, it can deliver very consistent, reliable results.
Supervised ML may require large amounts of historical data – as much needed to contain all relevant cases, i.e., for detecting product flaws, the data needs to contain a sufficient number of cases of flawed products. Labeling those massive data sets can be time-consuming and costly. In addition, training a model is something of an art. It requires a large amount of data, properly curated, to give good results. Today, this process is significantly simplified using tools such as AutoML, that benchmarks different ML algorithms. At the same time, over constraining the training process can result in a model that works very well on the training set but poorly on real-world data. Another key drawback is that supervised ML is not very effective at identifying unexpected trends in data or discovering new phenomena. For these types of applications, unsupervised ML can deliver better results.
Unsupervised ML
In contrast to supervised ML, unsupervised ML operates exclusively on unlabeled input. It provides a powerful tool for data exploration, discovering unknown patterns and associations without human assistance. The ability to operate on unlabeled data saves time and money and enables unsupervised ML to operate on data as quickly as that input is generated.
On the downside, unsupervised ML is more complex than supervised ML. It’s more expensive and requires greater levels of expertise, and often, more data Its output tends to be less dependable than that of supervised ML and ultimately requires human oversight for best results.
Common Unsupervised ML Techniques
Three important tasks for unsupervised ML are clustering, anomaly detection, and dimensionality reduction of data. Let’s take a closer look at each.
Clustering
As the name suggests, clustering involves analyzing datasets to identify shared characteristics among the data and group like instances together. Because clustering is an unsupervised ML technique, the algorithm, not a human being, determines the criteria for sorting. As a result, clustering can lead to surprising discoveries and is a great data exploration tool.
To envision how this might work: Imagine three people being asked to sort the fruit in a produce department. One might sort by type of fruit – citrus, stone fruit, tropical fruit, etc. Another might sort by color, while the third might sort by shape. Each method highlights a different set of characteristics.
Clustering can be divided into multiple types. The most common are:
- Exclusive clustering: A data instance is assigned exclusively to one cluster
- Fuzzy, or overlapping clustering: A data instance can be assigned to more than one cluster. A tangerine, for example, is both a citrus fruit and a tropical fruit. In the case of an unsupervised ML algorithm operating on unlabeled data, it’s possible to assign probabilities that the piece of data properly belongs to group A versus group B.
- Hierarchical clustering: Rather than a single set of clusters, this technique involves building a hierarchical structure of clustered data. Tangerines are citrus fruit, but they are also encompassed in the larger set of spherical fruit, which can further be absorbed by the set of all fruit.
Let’s look at a pair of the most popular clustering algorithms:
-
K-means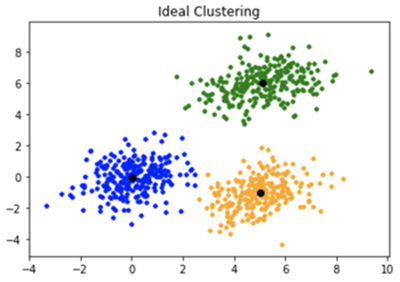
Figure 1: The K-means algorithm divides the data set into K clusters by first randomly selecting K data points as centroids and assigning the remaining instances randomly among the clusters. After calculating the mean for each data point, it assigns the centroids and the data points, then calculates the means again. The process continues until it has defined K well-behaved clusters with centroids. (Source: GeeksforGeeks)
The K-means algorithm sorts data into K clusters, where the value of K is preset by the user. At the beginning of the process, the algorithm randomly assigns K data points as the centroids for the K clusters. Next, it calculates the means between each data point and the centroid of its cluster. This results in a resorting of the data into the clusters. At this point, the algorithm recalculates the centroid and repeats the means calculation. It repeats the process of recalculating the centroid and re-sorting the cluster until it arrives at a constant solution (see Figure 1).
The K-means algorithm is simple and efficient. It is very useful for pattern recognition and data mining. On the downside, it requires some advance knowledge of the dataset to optimize the settings. It is also disproportionately affected by outliers.
- K-median
The K-median algorithm is a close cousin of K-means. It uses basically the same process, except that instead of calculating the mean for each data point, it calculates the median value. As a result, the algorithm is less sensitive to outliers.
Here are some common use cases for clustering:
- Clustering is effective for use cases like segmentation. This is commonly associated with customer analytics. It can also be applied to classes of asset, not just to analyze product quality and performance, but also to identify usage patterns that can affect product performance and lifetime. This can be helpful for OEMs managing “fleets” of assets such as automated mobile robots in smart warehouses or drones for inspection and data gathering.
- It can be used for image segmentation as part of an image processing operation.
- Clustering is also useful as a preprocessing step to help prepare data for supervised ML applications.
Anomaly Detection
Detection of anomalies can be critical for a variety of use cases ranging from defect detection to condition monitoring to cybersecurity. It’s a key task in unsupervised ML.
Fortunately, there are a variety of anomaly detection algorithms used in unsupervised ML. Let’s take a look at two of the most popular.
ROI Calculator

Discover the potential cost savings of robotic automation over a 20-year system life
This calculator compares your current manual labor costs against the total cost of owning and operating a robotic system over its 20-year lifespan.
- Isolation forest
The standard method for anomaly detection is to establish the set of normal values, then analyze each piece of data to see whether it departs from the norm and by how much. That’s an extremely time-consuming process when dealing with the kind of massive data sets used in ML. The isolation forest algorithm takes the opposite approach. It defines outliers as both infrequent and very different from the other instances in the data set. As a result, they are easier to isolate from the rest of the data set they on the other instances.
Isolation forest algorithms have minimal memory requirements, and the required time goes no more than linearly with the size of the data set. They can handle data of high dimensionality, even when it involves irrelevant attributes.
- Local outlier factor (LOF)
One of the challenges in identifying outliers by distance from the centroid alone is that a data point that is a short distance from a small cluster can be an outlier, while a point at a seemingly large distance from a large cluster may not be. The LOF algorithm is designed to make this distinction.
LOF defines an outlier as a data point whose local density deviation is much larger than that of its neighboring data points (see Figure 2). Although, like K-means, it does require some user settings in advance, it can be very effective. It can also be applied to novelty detection when used as a semi-supervised algorithm and trained only on normal data.
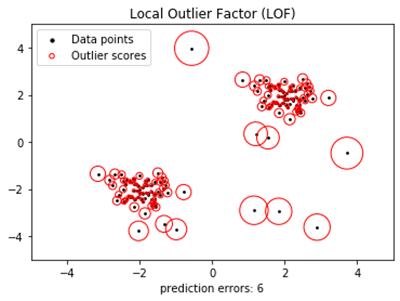 |
| Figure 2: Local outlier factor (LOF) uses local density deviation for each data point to calculate an anomaly score that makes a distinction between normal data points (low local density deviation) and outliers (high local density deviation). (Source: GeeksforGeeks) |
Below are several use cases for anomaly detection:
- Predictive maintenance: Most industrial equipment is built to last and operate with minimal downtime. As a result, there is often limited historical data with which to work. Because unsupervised ML can detect anomalous behavior even in limited data sets, it can potentially identify developing defects in these situations. Here too, it can be used for fleet management, providing early warning of defects while minimizing the amount of data that needs to be reviewed.
- Quality assurance/inspection: A machine that’s operating improperly can produce substandard product. Unsupervised ML can be used to monitor function and processes to flag anything unusual. Unlike standard QA processes, it can do so without labeling and training.
- Identification of image anomalies: This can be particularly useful in medical imaging to identify dangerous pathologies.
- Cybersecurity: One of the biggest challenges of cybersecurity is that the threats are constantly changing. In a case like this, anomaly detection through unsupervised ML can be very effective. A standard technique for security is to monitor data flow. If a PLC that normally sends commands to other components suddenly starts receiving a steady stream of commands from atypical devices or IP addresses, this can indicate an incursion. But what if the malicious code is coming from trusted sources (or bad actors spoofing trusted sources)? Unsupervised learning can detect bad actors by looking for atypical behavior in the equipment receiving the commands.
- Test data analysis: Testing plays an essential role in both design and production. Two of the biggest challenges involved are the sheer volume of data involved and the ability to analyze that data without introducing an inherent bias. Unsupervised ML can address both of those challenges. It can be a particular benefit in the development process or production troubleshooting, when testing teams are not even sure what they’re looking for.
Dimensionality Reduction
Machine learning is predicated on large amounts of data. That said, there are large amounts and overwhelmingly large amounts. A data set that can be winnowed down to 10, or even a few dozen features is one thing. The data set with thousands of features – and they most definitely exist – can be overwhelming. Accordingly, one of the first steps of machine learning can be dimensionality reduction to reduce the data to the most meaningful features.
A common algorithm for dimensionality reduction, pattern recognition, and data exploration is principal components analysis (PCA). A detailed discussion of this algorithm is beyond the scope of this article. Suffice it to say that it can help identify subsets of data that are orthogonal to one another – i.e., they can be removed from the data set without affecting the main analysis. PCA has several interesting use cases:
- Data preprocessing: When it comes to machine learning, the oft stated philosophy is more is better. That said, sometimes more is just more, particularly in the case of extraneous/redundant data. In these cases, unsupervised ML can be used to remove unnecessary features (data dimensions), speeding processing time and improving results. In the case of vision systems, unsupervised ML can be used for noise reduction.
- Image compression: PCA is very good at reducing the dimensionality of data sets while retaining meaningful information. This makes the algorithm very good at image compression.
- Pattern recognition: The same capabilities discussed above make PCA useful for tasks like facial recognition and other cases of complex image recognition.
Getting Started
Unsupervised ML is not better or worse than supervised ML. It is simply different. For the right project, it can be very effective. That said, the best rule of thumb is to keep it simple, so only use unsupervised ML on problems that cannot be addressed with supervised ML.
Below are several questions to ask to determine which class of machine learning is best for your project:
- What is the problem?
- What is the business case? What are the quantified goals? How quickly will the project deliver a return on investment? How does that compare to supervised learning or another more conventional solution?
- What type of input data is available? How much do you have? Is it relevant to the question you’re trying to answer? Are there processes that already produce labeled data, e.g., are there QA processes that identify flawed products? Is there a maintenance database that records equipment failure?
- Is it a good fit for unsupervised machine learning?
Finally, here are some tips to help ensure success:
- Do your homework and set up a strategy before beginning the project.
- Look for low hanging fruit – remember that identifying a key business case is essential.
- Start small – work out the bugs at a reduced scale.
- Make sure the solution is scalable, however – you don’t want to wind up in pilot-project purgatory.
- Consider working with a partner. All types of ML requires expertise. Look for the right tools and partners to automate things. Do not reinvent the wheel. You can either pay to develop the necessary skills in house or devote your resources to delivering the products and services you do best, while letting a partner and ecosystem handle the heavy lifting.
The data gathered in the industrial environment can be a valuable resource, but only when properly leveraged. Unsupervised ML can be a powerful tool for analyzing data sets to extract actionable insights. Adopting the technology can be challenging but it can provide a significant competitive advantage in a challenging world.
Acknowledgments
For their expertise in producing this article, the writer would like to thank Paul Ardis, technology manager for machine learning at GE Research (Niskayuna, New York), and Martin Schmitz, head of technical services at RapidMiner (Dortmund, Germany).
References
“Innovate manufacturing processes with cloud and AI”
Association for Advancing Automation
Discover how Association for Advancing Automation can support your automation journey with their complete range of solutions and expertise.
Visit Company Website



Tailor-made roller conveyor with the Aluminum Framing System
Customize your roller conveyor effortlessly with Montech's Aluminum Framing System. Ideal for flexible handling of product carriers and blister packaging