What Are Foundation Models?
Foundation models are large-scale artificial intelligence systems trained on vast, diverse datasets that can be adapted for multiple specialized tasks without requiring complete retraining. Unlike traditional AI models built for single specific purposes, foundation models learn general patterns and capabilities during training that transfer across domains, enabling them to perform tasks ranging from text generation to image analysis to robotic control.
The term "foundation" reflects these models serving as bases upon which specialized applications are built. A foundation model trained on billions of text examples develops language understanding applicable to translation, summarization, code generation, and question answering. Similarly, vision foundation models trained on millions of images can be fine-tuned for defect detection, object recognition, or quality inspection across different industries.
Foundation models emerged through advances in transformer architectures, massive computational resources, and the availability of internet-scale training data. Models like GPT (text), CLIP (vision-language), and SAM (image segmentation) demonstrate foundation model capabilities, with industrial applications now adapting these models for manufacturing automation, quality control, and robotic systems.
What Makes a Model Multimodal?
Multimodal models process and understand multiple types of data (text, images, video, sensor data) simultaneously, learning relationships between different modalities to enable tasks like image captioning, visual question answering, or robot control from natural language instructions.
Single-Modal Foundation Models
Traditional foundation models focus on one data type. Large language models (LLMs) like GPT process only text, learning language patterns, reasoning capabilities, and factual knowledge from written content. Vision models process images, learning to recognize objects, detect edges, and understand spatial relationships.
Single-modal models excel within their domain but cannot bridge between modalities. A text-only model cannot analyze images, and a vision-only model cannot generate textual descriptions of what it sees.
Multimodal Architecture
Multimodal models train on paired data linking different modalities. CLIP, for example, trains on millions of images with associated text descriptions, learning relationships between visual concepts and language. The model develops shared representations where related concepts (the word "robot" and images of robots) map to similar internal representations.
This architecture enables:
- Image understanding through text: Describing "find the red connector" to locate objects in images
- Text understanding through images: Generating captions describing image content
- Cross-modal reasoning: Answering questions about images or generating images from text descriptions
Industrial Multimodal Applications
Manufacturing benefits from multimodal capabilities:
Natural language robot control: Operators instruct robots using conversational language ("pick up the smaller part on the left") rather than programming specific coordinates. The multimodal model interprets language, identifies referenced objects in camera images, and generates appropriate robot commands.
Inspection with contextual understanding: Quality inspection systems that combine visual analysis with textual product specifications, understanding both what defects look like visually and how they're described in documentation.
Maintenance guidance: Systems that analyze equipment images while referencing maintenance manuals, providing context-aware troubleshooting by connecting visual symptoms to documented solutions.
How Do Small vs Large Foundation Models Compare?
Large foundation models (1-100+ billion parameters) offer superior general capabilities and reasoning but require substantial computational resources, while small foundation models (100 million to 7 billion parameters) provide adequate performance for specific tasks with dramatically lower hardware requirements and faster inference.
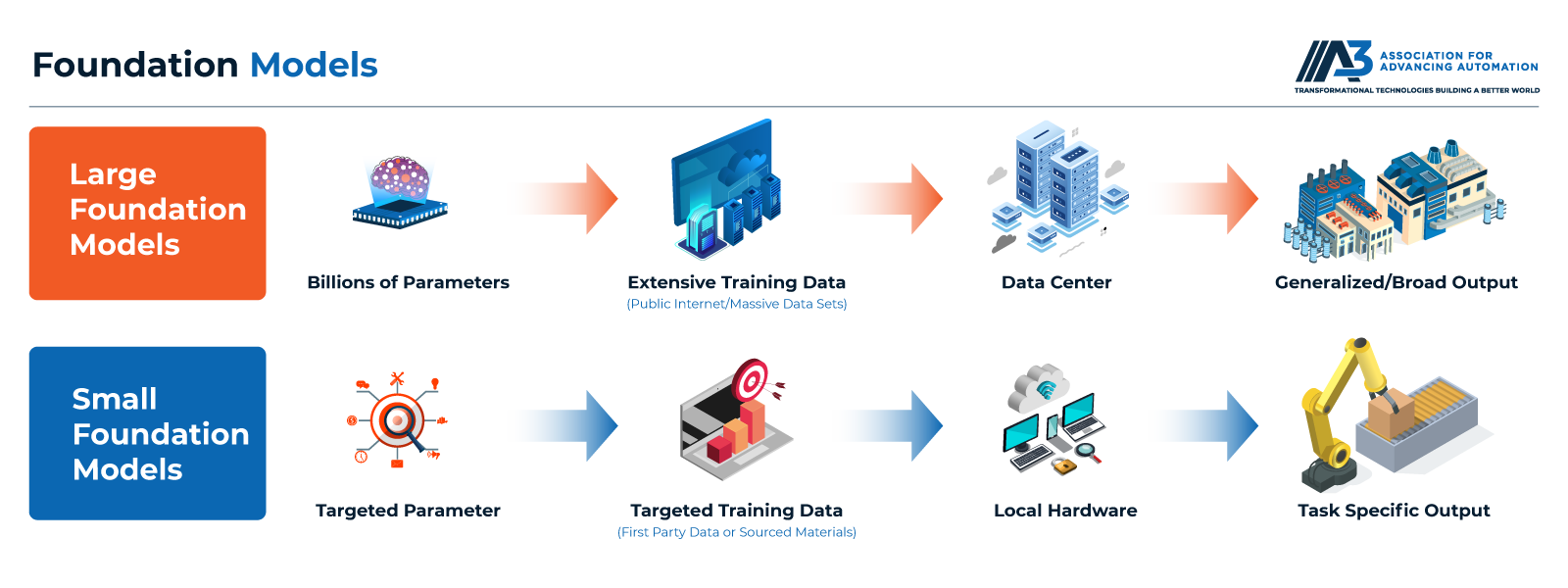
Large Foundation Models
Large language models like GPT-4 contain hundreds of billions of parameters, requiring:
- Training: Thousands of GPUs running for weeks to months, costing millions of dollars
- Inference: High-end GPUs or specialized AI accelerators
- Memory: 80-200+ GB for model weights
- Latency: 100-1000+ milliseconds per inference depending on hardware
These models demonstrate remarkable general capabilities including complex reasoning, multi-step problem solving, and broad knowledge across domains. However, their resource requirements limit deployment in industrial settings where cost, latency, and edge processing matter.
Small Foundation Models
Models with 100 million to 7 billion parameters offer practical alternatives:
- Training: Single or few GPUs, hours to days, accessible to more organizations
- Inference: Runs on industrial GPUs, edge AI accelerators, or even high-end CPUs
- Memory: 500 MB to 20 GB for model weights
- Latency: 20-200 milliseconds on appropriate hardware
Small models sacrifice some general capability and reasoning depth but maintain strong performance on targeted tasks when fine-tuned with domain-specific data. A 1-billion parameter model fine-tuned on manufacturing defects often outperforms a 100-billion parameter general model for that specific application.
LLM vs Small Model: Feature Comparison
| Feature | Large Foundation Models (LLMs) | Small Foundation Models |
|---|---|---|
| Parameter Count | 10B-100B+ parameters | 100M-7B parameters |
| Training Cost | Millions of dollars | Thousands to tens of thousands of dollars |
| Training Time | Weeks to months | Hours to days |
| Inference Hardware | High-end GPUs, cloud infrastructure | Edge AI accelerators, industrial GPUs |
| Memory Requirements | 80-200+ GB | 500 MB-20 GB |
| Inference Latency | 100-1000+ ms | 20-200 ms |
| General Capability | Exceptional reasoning, broad knowledge | Task-specific, requires fine-tuning |
| Edge Deployment | Impractical | Feasible with optimization |
| Ongoing Costs | High (cloud inference) | Lower (edge deployment possible) |
| Best For | Complex reasoning, general intelligence | Specific industrial tasks, real-time requirements |
Optimization and Distillation
Techniques exist to compress large models into smaller, faster versions:
Knowledge distillation: Training small models to mimic large model outputs, transferring capabilities while reducing size. A 70-billion parameter model might distill into a 7-billion parameter version retaining 90-95% of performance for specific tasks.
Quantization: Reducing numerical precision (from 32-bit to 8-bit or 4-bit), cutting memory requirements by 4-8x with minimal accuracy loss. This enables running larger models on less powerful hardware.
Pruning: Removing redundant parameters identified as contributing minimally to performance, creating sparser models requiring less computation.
These techniques make foundation model deployment practical in industrial environments where edge processing, low latency, and cost constraints matter.
What Industrial Applications Use Foundation Models?
Quality inspection and defect detection, robot programming and control, predictive maintenance, supply chain optimization, and technical documentation search use foundation models to automate tasks previously requiring extensive custom development or human expertise.
Quality Inspection and Defect Detection
Vision foundation models like SAM (Segment Anything Model) enable zero-shot or few-shot defect detection. Traditional approaches require hundreds of labeled defect examples and algorithm engineering. Foundation models identify anomalies with minimal examples by leveraging general visual understanding learned during pre-training.
Applications include:
- Surface defect detection on variable materials (textiles, wood, metal castings) where defect appearance varies significantly
- Assembly verification confirming component presence and correct installation across product variants
- Packaging inspection detecting damage, label issues, or foreign objects
Foundation models handle appearance variability and new defect types more gracefully than traditional rule-based systems, reducing setup time and improving adaptability to changing product lines.
Natural Language Robot Programming
Large language models enable programming robots through conversational interaction rather than traditional teach pendants or code. An operator describes desired behavior ("pick parts from the left bin and place them in rows on the pallet"), and the foundation model generates appropriate robot programs.
This approach:
- Reduces programming time from hours to minutes
- Enables non-programmers to deploy robotic automation
- Simplifies reconfiguration when tasks change
- Provides more intuitive human-robot interaction
Multimodal models combine language understanding with vision, enabling robots to interpret context ("the damaged parts," "the heavier boxes") by analyzing both linguistic references and visual scenes.
Predictive Maintenance
Foundation models analyze sensor data (vibration, temperature, current, acoustic signatures) to predict equipment failures. Unlike traditional approaches requiring extensive feature engineering, foundation models learn relevant patterns directly from time-series data.
Industrial applications:
- Motor and bearing failure prediction from vibration signatures
- Pump and compressor monitoring detecting performance degradation
- Robot joint condition assessment predicting lubrication needs or wear
Foundation models generalize across similar equipment types, learning failure patterns from one installation and applying insights to others, accelerating deployment and improving prediction accuracy.
Supply Chain and Logistics Optimization
Foundation models analyze historical data, real-time conditions, and textual information (orders, specifications, documentation) to optimize inventory, scheduling, and resource allocation. Multimodal capabilities enable incorporating diverse data sources (sensor readings, text documents, visual inspections) into unified optimization frameworks.
Technical Documentation and Knowledge Management
Large language models search, summarize, and answer questions from technical documentation, maintenance manuals, and historical records. Manufacturing organizations use foundation models to:
- Provide technicians instant answers from thousands of pages of documentation
- Generate maintenance procedures customized for specific equipment conditions
- Translate technical specifications across languages
- Extract insights from decades of maintenance logs and incident reports
This transforms unstructured knowledge into accessible, actionable information supporting faster problem resolution and improved operational efficiency.
Conclusion
Foundation models represent a paradigm shift in industrial AI, moving from task-specific models requiring extensive custom development toward adaptable systems that transfer knowledge across applications. Large foundation models demonstrate remarkable general capabilities but demand substantial computational resources, while small models offer practical alternatives for edge deployment and real-time industrial applications.
Multimodal foundation models bridge between data types, enabling more natural human-machine interaction and richer understanding of industrial environments. The ability to process both visual and linguistic information creates opportunities for intuitive robot programming, context-aware quality inspection, and intelligent maintenance systems.
Industrial adoption of foundation models is accelerating as model compression techniques, specialized hardware, and fine-tuning methodologies make deployment practical in manufacturing environments. Understanding the trade-offs between large and small models, recognizing appropriate applications, and selecting suitable architectures enables organizations to leverage foundation model capabilities while meeting industrial requirements for reliability, latency, and cost-effectiveness.
Back to Glossary